Databricks Alerts
The Databricks Alerts feature allows USERs and ADMINs to monitor their Databricks environment through alert notifications. With this feature, you can receive timely notifications about anomalies in cluster and warehouse costs, failed jobs and queries, and long-running workloads.
Prerequisites
User Permissions: ADMIN can configure alert settings for all users, while USER can only configure alert settings for themselves.
Accessing the Alerts Feature
-
Navigation:
From the main dashboard, click on the Settings option in the left-hand menu, then select Alert Settings. -
Dashboard Overview:
Upon accessing the Alert Settings section, you will see the available alert configurations. If both Databricks and Snowflake products are enabled, you will see two tabs. Select the Databricks tab to configure Databricks alerts.
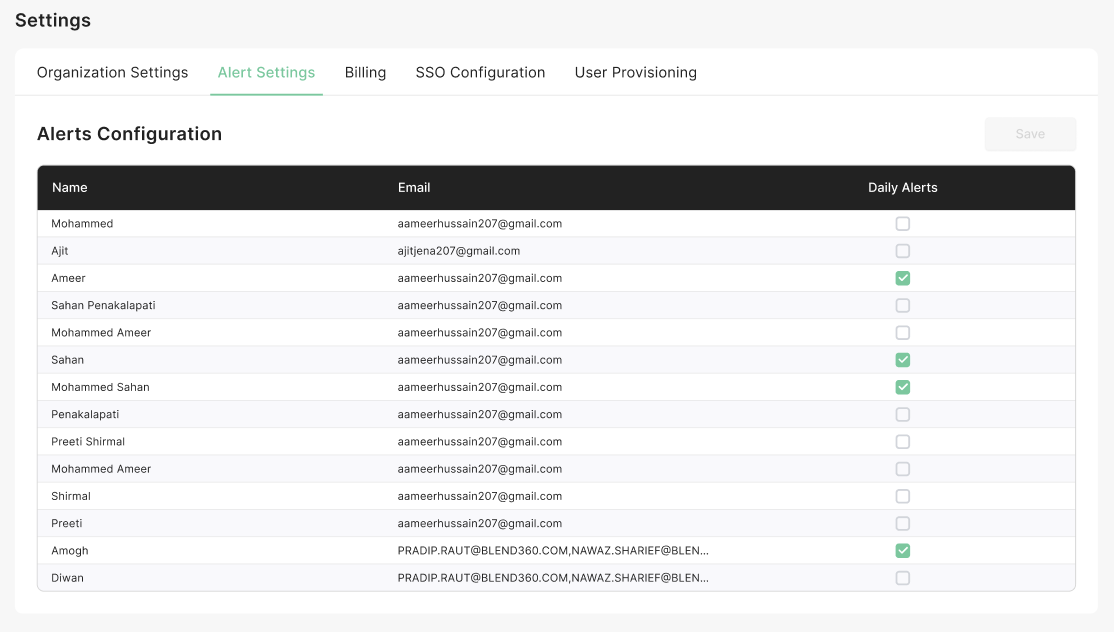
Alert Preferences
Currently, all alerts are delivered via email. In future updates (Phase 2), additional delivery methods such as Slack and Teams will be available.
Daily Summary Alert
The Daily Summary Alert provides a comprehensive overview of your Databricks environment, including key metrics and anomalies detected in the previous day.
- Frequency: Daily
- Type:
- Total daily usage metrics
- Cluster and Warehouse anomalies
- Workload Failures
- Long-running workloads
Refer to the sample alert format below:

Best Practices for Effective Alert Management
To get the most value from your Databricks Alerts, consider these best practices:
-
Review Daily Summaries: Make it a habit to review your daily summary alerts to identify trends and patterns before they become problems.
-
Follow Up on Anomalies: When you receive an anomaly alert, investigate the cause promptly to determine if it's a legitimate issue or a planned increase in resource usage.
-
Address Failed Workloads: Failed jobs and queries can indicate underlying issues with your Databricks implementation. Regularly review and address these failures.
-
Optimize Long-Running Workloads: Long-running workloads can unnecessarily consume resources. Use the information in these alerts to identify optimization opportunities.
For any issues or further assistance, please refer to the in-app help or contact our support team.